This week’s #sqlnewblogger posts!
SQL New Blogger Challenge November 2015 Edition – Week 3 Digest
Reply

This week’s #sqlnewblogger posts!
I have a situation where I need to retrieve the data in an encrypted column from, but don’t want to give all my users access to the symmetric key used to encrypt that column. The data is of the sort where it’s important for the application to produce the required output, but if a user runs the stored procedure to see what the application is getting from it, it’s not critical that they see this one field.
The catch is that if the stored procedure is written with the assumption that the caller has permission to access the encryption key or its certificate, they’ll get an error. After a bit of research and pondering later, I came up with two options:
Let’s check out option 2. This example is simplified from my actual scenario to demonstrate the idea.
declare @BankId varchar(6) = '123456';
SELECT cast('' as varchar(50)) AS AccountNum,
,AccountName
,AccountOwner
INTO #AccountData
FROM dbo.Accounts
WHERE OriginatingBank = @BankId
AND AccountType = 'Checking'
DECLARE @AcctNo VARCHAR(30);
BEGIN TRY
OPEN SYMMETRIC KEY MyKey DECRYPTION BY CERTIFICATE My_Cert
SELECT @AcctNo = CONVERT(VARCHAR, decryptbykey(AccountNum))
FROM dbo.Accounts
WHERE OriginatingBank = @BankId
AND AccountType = 'Checking'
CLOSE SYMMETRIC KEY MyKey
END TRY
BEGIN CATCH
SET @AcctNo = 'Access Restricted';
END CATCH
UPDATE #AccountData SET AccountNum = @AcctNo;
SELECT * FROM #AccountData;
DROP TABLE #AccountData;
TRY/CATCH in T-SQL works similarly to how it does in languages like C# or PowerShell. It allows you to attempt an operation and take care of any error conditions fairly easily.
In this case, I’m attempting to open the encryption key. But if the user doesn’t have permission to do so, it doesn’t terminate the stored procedure with an error. Instead, it jumps to the CATCH block, where I’ve defined an alternate way of handling the situation. Here, if the user doesn’t have the appropriate permissions, they’ll just get “Access Restricted” for the account number, and access to that sensitive data is a little more tightly controlled – while still letting users access the data they do need.

The one wizard you can trust
If you need to move data from one table into a new table, or even tables in a database into another database, the Import/Export Wizard in SQL Server Management Studio looks pretty tempting. Set up a source & destination, click a few buttons, kick back with a cup of tea and watch the progress bars, right?
It turns out that the wizard just isn’t as smart as it may seem. If you’re not careful, you won’t get what you’re expecting. Let’s check it out.
We’ll start by creating a real simple table in a database, containing a primary key and a computed column.
Create table sample.dbo.SourceTable ( RowId int identity(1,1) not null primary key, Num1 int not null, Num2 int not null, Total as (Num1+Num2) );
Let’s populate it with a few rows of data, then update some of that data to make sure the computed column is working. Remember, this is just to demonstrate the idea.
insert into sample.dbo.SourceTable (Num1, Num2) values (1,2); go 100 select top 5 * from sample.dbo.SourceTable order by RowId; update sample.dbo.SourceTable set Num1 = Num1 * RowId where RowId <= 3; select top 5 * from sample.dbo.SourceTable order by RowId;
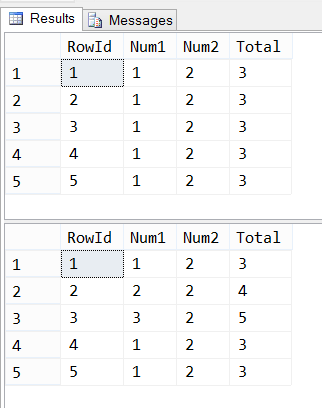
Great! We’ve got data, the computed columns are working, let’s copy it over to a new table in another database. We’ll just going to click Next, Next, Next through the wizard this time around.
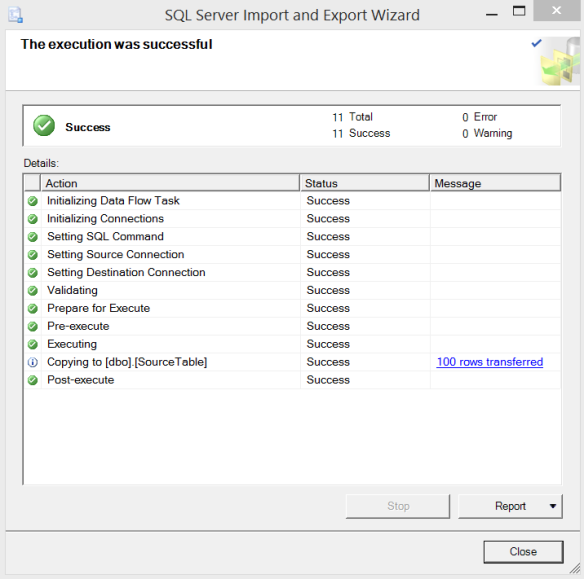
Success! Our table has been copied and the data’s all there.
select top 5 * from Sample2.dbo.SourceTable order by RowId;
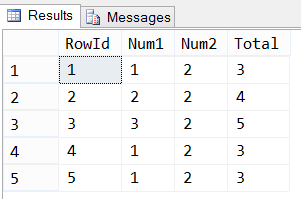
Let’s do some work on our new table and check out the results.
select top 5 * from Sample2.dbo.SourceTable order by RowId; update Sample2.dbo.SourceTable set Num2 = Num2 * RowId where RowId < 3; select top 5 * from Sample2.dbo.SourceTable order by RowId;
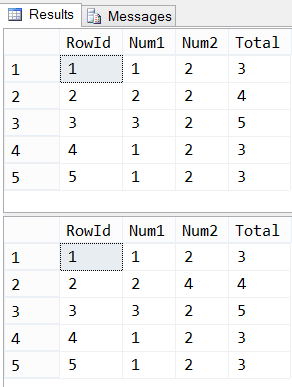
Woah! That’s not right. That Total column is supposed to be Num1 + Num2, and last time I checked 2 + 4 was not 4. Let’s keep going and try adding a new record the same way it was done earlier.
insert into Sample2.dbo.SourceTable (Num1, Num2) values (100,200);
Cannot insert the value NULL into column 'RowId', table 'Sample2.dbo.SourceTable'; column does not allow nulls. INSERT fails.
Huh. Now that’s really odd, isn’t it? RowId is supposed to be an identity – we shouldn’t have to populate it. What is going on here? Let’s script out the table.
USE [Sample2] GO /****** Object: Table [dbo].[SourceTable] Script Date: 2015-11-10 22:36:23 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[SourceTable]( [RowId] [int] NOT NULL, [Num1] [int] NOT NULL, [Num2] [int] NOT NULL, [Total] [int] NULL ) ON [PRIMARY] GO
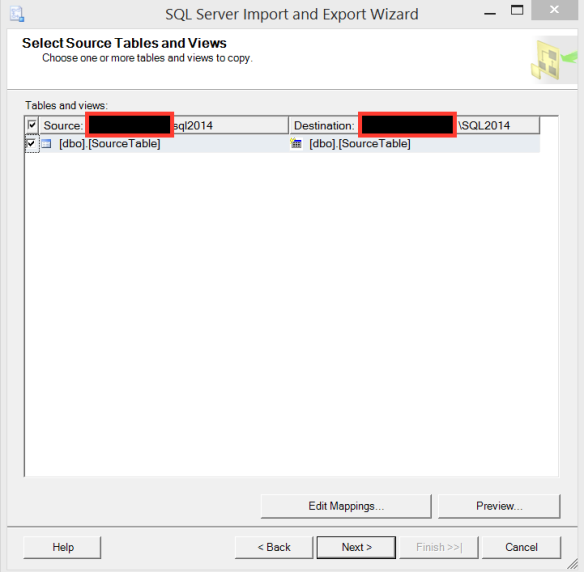
This is all kinds of wrong! What happened to the primary key? Or the computed column? Well, it turns out that the wizard isn’t that smart, and if you just take all the default values, you’re going to get burned. Let’s go back to the wizard and click that Edit Mappings button in the Select Source Tables and Views screen.
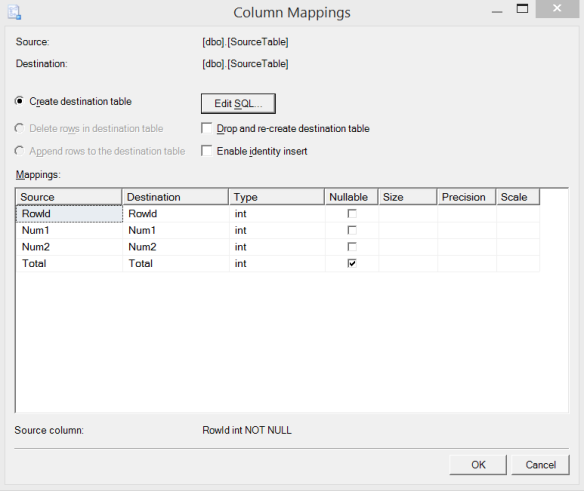
Well…that looks like what we got above. And it’s not what we wanted. If we click Edit SQL, this is confirmed – the table being created is not defined the same way the source table is being defined.
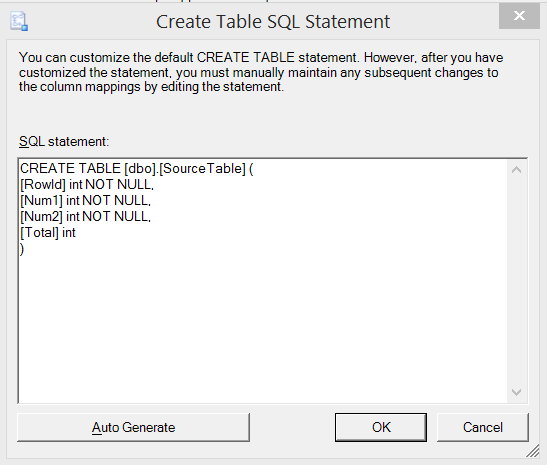
Fortunately, we can edit the SQL here and make it match the source table definition, then finish the wizard.
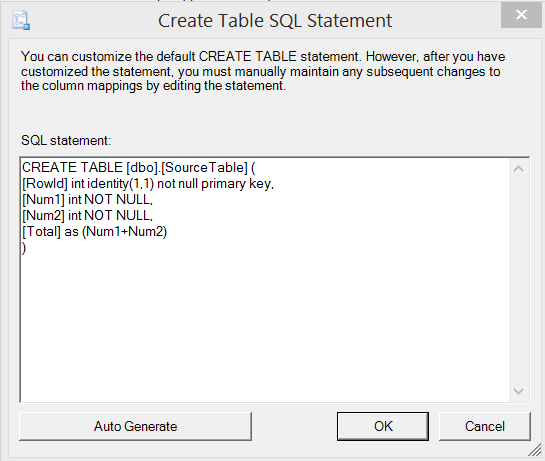
OK, data’s copied – what do we have?
select top 5 * from Sample3.dbo.SourceTable order by RowId; update Sample3.dbo.SourceTable set Num2 = Num2 * RowId where RowId < 3; select top 5 * from Sample3.dbo.SourceTable order by RowId; insert into Sample3.dbo.SourceTable (Num1, Num2) values (100,200); select * from sample3.dbo.SourceTable where rowid >= 100 order by RowId;
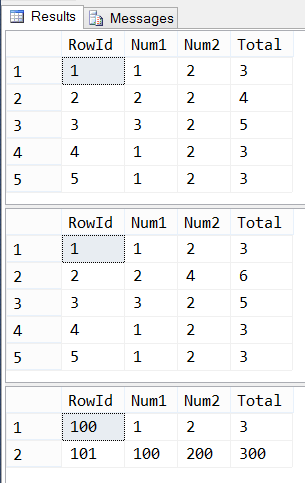
Everything’s there, and it’s working the way it’s supposed to. Lesson learned: don’t blindly trust the defaults, especially the ones in a wizard. Double-check everything, and then verify that your schema works the way you expect it to before doing any business with it.
Ed Leighton-Dick has renewed his New Blogger Challenge this month. Here are all (I think) the posts for this week after Ed posted his announcement. If I’ve missed any, please let me know and I’ll update.
This week marks the end of Ed Leighton-Dick’s New Blogger Challenge. It’s terrific seeing everyone sticking with the challenge all month and I’m looking forward to catching up with all the posts. Great job, everyone! Keep going!
We hear the common refrain among DBAs all the time. Back up your data! Test your restores! If you can’t restore the backup, it’s worthless. And yes, absolutely, you have to back up your databases – your job, and the company, depend upon it.
But are you backing everything up?
Saturday night was an ordinary night. It was getting late, and I was about to put my computer to sleep so I could do likewise. Suddenly, everything on my screen was replaced with a very nice message telling me that something had gone wrong and my computer needed to be restarted.
Uh oh.
In 7 1/2 years of using OS X, I’ve had something like this happen maybe 4 times.
After waiting whet felt like an eternity, the system finished booting & I got back into my applications. I opened up PowerPoint, as I had it open before the crash so I could work on my SQL Saturday Rochester slide deck whenever inspiration struck. I opened my file, and was greeted by nothingness. I flipped over to Finder and saw zero bytes displayed as the file size.
Uh oh.
“But Andy,” you say, “you use CrashPlan, right? Can’t you just recover the file from there?” Well, you’re half right. I do use CrashPlan. I even have a local, external hard drive (two, actually) that I back up to in addition to CrashPlan’s cloud service. But I couldn’t recover from any of those.

Because Dropbox is already “in the cloud”, I had opted to not back it up with CrashPlan when I first set it up. After all, it’s already a backup right? It’s not my only copy, it’s offsite, it’s all good.
Not so fast. When my system came back up, Dropbox dutifully synced everything that had changed – including my now-empty file.
![]()
So, now what? Fortunately, Dropbox allows you to revert to older versions, and I was able to select my last good version and restore it.

I broke The Computer Backup Rule of Three and very nearly regretted it. For my presentation:
Even scarier, if Dropbox didn’t have a version history or it had taken me more than 30 days to realize that this file had been truncated, I’d have lost it completely.
Everything else on my computer was in compliance with the Rule Of Three; I just got lazy with the data in my Dropbox and Google Drive folders. I’ve since updated my CrashPlan settings to include my local Dropbox and Google Drive folders so that my presentation should now be fully protected:
And don’t forget to test those backups before you need to use them. Dropbox, Google Drive and other online file storage/sync solutions are very useful, but you cannot rely upon them as backups. I don’t think you’ll ever regret having “extra” backups of your data, as long as that process is automatic.
Here are the posts collected from week three of the SQL New Blogger Challenge. It’s been compiled the same way previous weeks’ posts were. Everyone’s doing a great job keeping up with the challenge!
Fixed-position data formats will seemingly be with us forever. Despite the relative ease of parsing CSV (or other delimited formats), or even XML, many data exchanges require a fixed-position input. Characters 1-10 are X, characters 11-15 are Y and if the source data is fewer than 5 characters, we have to left-pad with a filler character, etc. When you’re accustomed to working with data that says what it means and means what it says, having to add “extra fluff” like left-padding your integers with a half-dozen zeroes can be a hassle.
I received a draft of a stored procedure recently which had to do exactly this. The intent is for the procedure to output the data almost entirely formatted as required, one record per line in the output file, and dump the result set to a file on disk. As it was given to me, the procedure was peppered with CASE statements like this (only more complex) in the SELECT clause:
-- Method 1 select case len(cast(logid as varchar)) when 9 then '0' + cast(logid as varchar) when 8 then '00' + cast(logid as varchar) when 7 then '000' + cast(logid as varchar) when 6 then '0000' + cast(logid as varchar) when 5 then '00000' + cast(logid as varchar) when 4 then '000000' + cast(logid as varchar) when 3 then '0000000' + cast(logid as varchar) when 2 then '00000000' + cast(logid as varchar) when 1 then '000000000' + cast(logid as varchar) when 0 then '0000000000' + cast(logid as varchar) end as logid ,logtext from cachedb.dbo.logs;
It’s perfectly valid, it works, and there’s nothing inherently wrong with it. But I find it a bit tough to read, and it could become trouble if the format changes later, as additional (or fewer) cases will have to be accounted for. Fortunately, the day I received this procedure was right around the day I learned about the REPLICATE() T-SQL function. Maybe we can make this simpler:
select replicate('0',10-len(cast(logid as varchar))) + cast(logid as varchar) as logid,logtext from cachedb.dbo.logs;
Not bad. But it leaves us with a magic number and similar to the previous example, if the file format changes we have to seek out these magic numbers and fix them. This is easily remedied by defining these field lengths at the beginning of the procedure, so that they’re all in one place if anything needs to change.
-- Method 2
declare @paddedlength int = 10;
select replicate('0',@paddedlength-len(cast(logid as varchar))) + cast(logid as varchar) as logid,logtext from cachedb.dbo.logs;
Yet another approach would be to pad out the value beyond what we need, then trim the resulting string back to the required length. Again, we have to be careful to not leave ourselves with magic numbers; the solution is the same as when using REPLICATE():
-- Method 3
select right('0000000000' + cast(logid as varchar), 10) as logid,logtext from cachedb.dbo.logs;
-- Or, with more flexibility/fewer magic numbers
-- Method 4
declare @paddedlength int = 10;
select right(replicate('0',@paddedlength) + cast(logid as varchar), @paddedlength) as logid,logtext from cachedb.dbo.logs;
All four methods yield the same results, as far as the data itself is concerned. But what about performance? For a table with 523,732 records, execution times were:
Each method had an identical execution plan, so I’m probably going to opt for the code that’s more readable and maintainable – method 2 or 4.
As with any tuning, be sure to test with your own data & queries.
I didn’t intend for last week’s digest to also be my post for week two of the challenge, but life got in the way and I wasn’t able to complete the post that I really wanted in time. So, that post will be written much earlier in week three and completed well ahead of the deadline.
Here are the posts collected from week two of the SQL New Blogger Challenge. It’s been compiled the same way last week’s was.
Watching all of the tweets as people posted their first entries in the SQL New Blogger Challenge earlier this week, I quickly realized that keeping up was going to be a challenge of its own. Fortunately, there are ways to reign it in.
My first stop was IFTTT (If This Then That). IFTTT allows you to create simple “recipes” to watch for specific events/conditions, then perform an action. They have over 175 “channels” to choose from, each of which has one or more triggers (events) and actions. I have IFTTT linked to both my Google and Twitter accounts, which allowed me to create a recipe which watches Twitter for the #sqlnewblogger hashtag, and writes any tweets that match it to a spreadsheet on my Google Drive account (I’ll make the spreadsheet public for now, why not?).
The next step is to export the spreadsheet to CSV. I don’t have this automated, and may not be able to (I may have to find another workaround). Once it’s a CSV, I can go to PowerShell to parse my data. I want the end result to be an HTML table showing each post’s author (with a link to their Twitter stream) and a link to the post (using the title of the post itself).
Once I import the CSV file into an object in my PowerShell script, I need to do some filtering. I don’t want to be collecting all the retweets (posts starting with RT), and I should probably exclude any post that doesn’t contain a URL (looking for the string HTTP).
To extract the post URLs, I ran a regular expression against each tweet. Twitter uses their own URL shortener (of course), which makes this pretty easy – I know the hostname is t.co, and after the slash is an alphanumeric string. The regex to match this is fairly simple: [http|https]+://t.co/[a-zA-Z0-9]+
Then, for each URL found in the tweet, I use Invoke-WebRequest to fetch the page. This cmdlet automatically follows any HTTP redirects (I was afraid I’d have to do this myself), so the object returned is the real destination page. Invoke-WebRequest also returns the parsed HTML of the page (assuming you use the right HTTP method), so I can extract the title easily instead of having to parse the content myself. It’ll also give me the “final” URL (the destination reached after all the redirects). Easy!
My full script:
#requires -version 3
[cmdletbinding()]
param ()
set-strictmode -Version latest;
Add-Type -AssemblyName System.Web;
$AllTweets = import-csv -path 'C:\Dropbox\MiscScripts\Sqlnewblogger tweets - Sheet1.csv' | where-object {$_.text -notlike "RT *" -and $_.text -like "*http*"} | select-object -property "Tweet By",Text,Created | Sort-Object -property created -Unique;
$TweetLinks = @();
foreach ($Tweet in $AllTweets) {
$Tweet.text -match '([http|https]+://t.co/[a-zA-Z0-9]+)' | out-null;
foreach ($URL in $Matches) {
$MyURL = $URL.Item(0);
# Invoke-WebRequest automatically follows HTTP Redirects. We can override this with -MaxRedirection 0 but in this case, we want it!
$URLCheck = Invoke-WebRequest -Method Get -Uri $MyUrl;
$OrigUrl = $URLCheck.BaseResponse.ResponseUri;
write-debug $Tweet.'Tweet By';
Write-debug $URLCheck.ParsedHtml.title;
write-debug $URLCheck.BaseResponse.ResponseUri;
$TweetLinks += new-object -TypeName PSObject -Property @{"Author"=$Tweet.'Tweet By';"Title"=$URLCheck.ParsedHtml.title;"URL"=$URLCheck.BaseResponse.ResponseUri;};
}
}
Write-debug $TweetLinks;
$TableOutput = "<table><thead><tr><td>Author</td><td>Post</td></tr></thead><tbody>";
foreach ($TweetLink in $TweetLinks) {
$TableOutput += "<tr><td><a href=""https://twitter.com/$($TweetLink.Author.replace('@',''))"">$($TweetLink.Author)</a></td><td><a href=""$($TweetLink.URL)"">$([System.Web.HttpUtility]::HtmlEncode($TweetLink.Title))</a></td></tr>";
}
$TableOutput += "</tbody></table>";
$TableOutput;
And now, my digest of the first week of the SQL New Blogger Challenge. This is not a complete listing because I didn’t think to set up the IFTTT recipe until after things started. I also gave people the benefit of the doubt on the timing (accounting for timezones, etc.) and included a few posted in the early hours of April 8th. For week 2, it will be more complete.
There are a couple limitations and gotchas with this process:
